# 3. xKnown Agent Layer: Intelligent Data Value Extraction Architecture
### 3.1 Architecture Overview
The Agent Layer uses an AI-driven decision architecture where AI Agents\[1]\[2] autonomously discover, evaluate, and extract data value from voice inputs gathered via hardware devices. Moving beyond rule-based systems, it leverages ML models and LLMs for logical reasoning and valuation.
#### 3.1.1 Design Principles
* AI Agent First: Core decisions are AI-led, with rule engines offering auxiliary fallback.
* Value Discovery Driven: Prioritizes uncovering commercial value within the data itself.
* Privacy by Design: Ensures privacy compliance throughout processing, mitigating leakage risks.
#### 3.1.2 System Modules
* Data Collection & Storage: Encrypted, anonymized data uploaded to distributed data lake.
* Pre-Processing: Speech transcription, semantic parsing, sentiment analysis generates structured data.
* AI Agent Valuation: Deep analysis outputs scoring and labels.
* Task Orchestration: Coordinates data flow, task scheduling, and decision execution.

### 3.2 Data Collection and Storage
#### **3.2.1 Collection Process**
In this phase, voice data is collected using customized hardware firmware. Devices apply local noise reduction algorithms to eliminate environmental noise. Embedded encryption algorithms (symmetric or hybrid) encrypt raw data for secure transmission. Before upload, sensitive information such as names, phone numbers, and addresses is anonymized through keyword dictionaries and entity recognition models.
For unstable network environments, segmented transmission is used. Audio recordings are split into multiple fragments, each uploaded independently with breakpoint resumption capability for interrupted uploads.
Uploaded data is stored in xKnown's distributed data lake, utilizing object storage technology with version control and redundant backups to ensure data security and availability.
#### **3.2.2 Data Privacy and Security**
* **End-to-End Encryption:** Full-chain encryption from device to cloud using TLS and application-level encryption.
* **Local Anonymization:** Sensitive entity recognition, rule filtering, and content labeling ensure personal data is stripped prior to upload.
* **Access Control:** Role-based access control (RBAC) and least privilege principles restrict module-level access rights.
* **Audit Logs:** All data access is logged for security auditing and traceability.
#### **3.2.3 Data Processing Workflow**
* **Pre-processing Trigger:** The orchestration system fetches new data batches for speech recognition and transcription.
* **Semantic Structuring:** NLP models extract keywords, identify topics, disambiguate semantics, and generate sentiment labels, outputting standardized structured formats.
* **Value Evaluation Execution:** Structured data is scored by AI Agent models using multi-factor valuation logic.
* **Incentive Coefficient Calculation:** Contributor incentive coefficients are calculated based on data value, scarcity, and other multi-dimensional factors.
* **Storage Confirmation:** Each uploaded data fragment is assigned a unique identifier with version control and archived.
* **Ownership Synchronization On-chain:** After all processing is complete, data hashes and user DIDs are written to the blockchain to finalize ownership confirmation.

### 3.3 Data Pre-processing Module
#### **3.3.1 Speech Recognition and Transcription**
Audio data enters ASR models trained on industry-specific corpora. Acoustic and language models jointly infer transcripts, handling accents, speeds, and technical terms robustly. Custom hotword dictionaries can be added for specialized domains.
#### **3.3.2 Semantic Parsing and Sentiment Analysis**
* **Lexical Analysis:** Converts sentences into part-of-speech tags and dependency trees.
* **Keyword Extraction:** Identifies core topic words and entities.
* **Topic Classification:** Uses LLMs for contextual understanding and topic recognition.
* **Disambiguation:** Sliding window context adjusts word sense interpretations.
* **Sentiment Analysis:** Multi-classifiers label sentiment (positive, neutral, negative) with confidence scores.
#### **3.3.3 Standardization and Structuring**
* **Character Encoding:** Unified formats like UTF-8.
* **Timeline Alignment:** Uses timestamps and speaker separation models.
* **Noise Filtering:** Removes duplicates, silence, and irrelevant segments.
* **Output Format:** {Speaker ID, Timestamp, Text Content, Topic Tags, Sentiment Tags}.
### 3.4 AI Agent Valuation Module
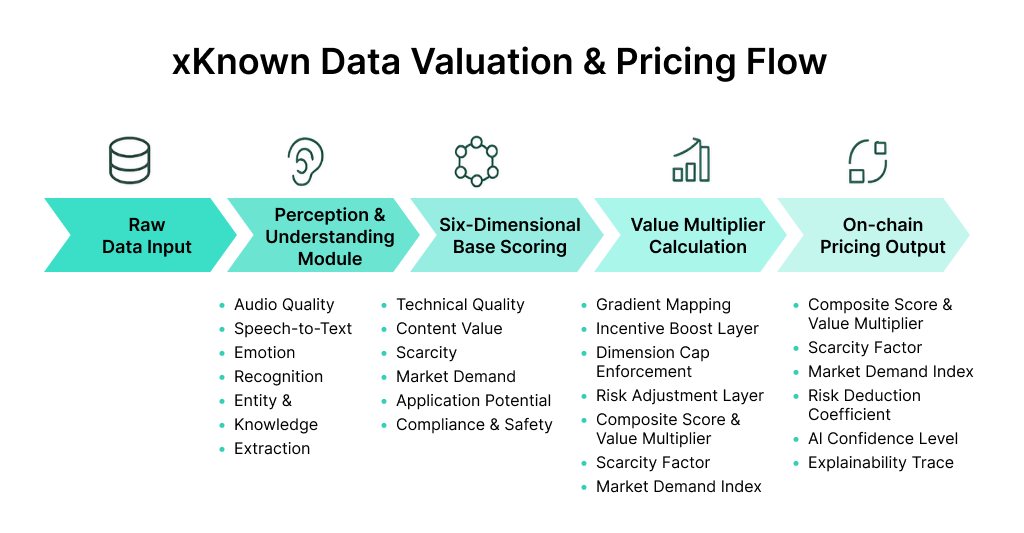
Within the xKnown ecosystem, the Agent Layer serves as the intelligent core of the entire data valuation process, performing end-to-end, automated evaluation of voice data, transforming raw audio into fully quantified digital assets. The system’s core valuation workflow consists of five key stages:
#### 3.4.1 Intelligent Perception and Semantic Understanding
The valuation process begins with multimodal perception. The system first conducts comprehensive quality checks on the incoming audio data, evaluating technical parameters such as signal-to-noise ratio (SNR), sampling rate, and data completeness to ensure data usability. Real-time transcription is then performed across more than 30 languages using state-of-the-art speech recognition models (e.g., Whisper, Wav2Vec2). Simultaneously, emotional features such as tone and sentiment are extracted through transformer-based emotion classification models. Speaker identity features are captured via advanced speaker embedding algorithms (e.g., x-vector, ECAPA-TDNN), enabling individual-level deduplication and traceability.
Once transcription is complete, the semantic understanding module is activated. This module generates deep semantic embeddings using models such as BERT and RoBERTa, quantifying linguistic logic, information density, and domain complexity. Named entity recognition automatically extracts key entities such as people, organizations, locations, and events, while knowledge relationship extraction (e.g., OpenIE) identifies logical dependencies and causal chains, further enriching data structure. A fusion algorithm integrates both semantic and emotional dimensions to construct a comprehensive semantic profile for each data record.
#### **3.4.2 Scenario Identification and Commercial Value Estimation**
Following semantic analysis, the scenario recognition module evaluates the data’s real-world application context and commercial potential. Acoustic scene classification models identify recording environments (e.g., meeting rooms, construction sites, outdoor spaces). Dialogue pattern detection algorithms classify the conversation type (monologue, multi-party discussion, or interview). Industry domain classification is automatically performed based on language patterns and domain-specific keywords (e.g., healthcare, legal, education, finance). Leveraging historical market data, the system applies gradient boosting models (e.g., XGBoost) to estimate the potential market value of the data for AI training marketplaces. Contextual metadata such as timestamps, device state, and geographic location are incorporated to construct a holistic usage profile for each dataset.
#### **3.4.3 Six-Dimensional Valuation Model and Hybrid Decision Engine**
All semantic and contextual insights are fed into xKnown’s proprietary Hybrid Valuation Engine, which combines AI-driven inference with rule-based scoring logic:
AI Agent Layer\[3]: Advanced language models (e.g., GPT-4, Claude) apply complex reasoning based on structured prompt engineering, generating comprehensive valuation outputs and confidence scores.
Rule Engine Layer: Traditional rule-based algorithms apply long-standing scoring weights and consistency rules to normalize technical metrics such as length, sampling rate, SNR, and semantic density.
Fusion Decision Layer: Bayesian inference algorithms integrate both AI and rule-based evaluations, balancing decision flexibility with system stability.
Anomaly Detection & Traceability: Built-in safeguards ensure transparency and auditability under outliers, noisy data, or edge cases, while maintaining interpretability.
The six core valuation dimensions include:
* Technical Quality: Foundational data usability metrics.
* Content Value: Semantic depth and informational complexity.
* Scarcity: Linguistic uniqueness and corpus rarity.
* Market Demand: Dynamic supply-demand indicators and enterprise training needs.
* Application Potential: Suitability for AI model training and transfer learning.
* Compliance & Safety: Legal, privacy, and regulatory compliance screening.

These six dimensions collectively determine the core multiplier logic of data valuation, which, when combined with incentive coefficients, directly inform final revenue allocation weights.
#### **3.4.4 Scarcity, Market Forecasting, and Risk Control Agents**
Beyond the core valuation system, xKnown deploys three auxiliary Agent modules to enhance value precision and control systemic risks:
Scarcity Discovery Agent: Quantifies linguistic rarity, content uniqueness, and temporal novelty using global language frequency databases, local-sensitive hashing (LSH) for de-duplication, and semantic embedding comparisons. The resulting scarcity score is directly applied to high-multiplier incentives.
Market Prediction Agent: Forecasts future demand for data assets using time-series models (e.g., LSTM, Prophet), supply-demand simulations, price elasticity analysis, and Monte Carlo scenario modeling. It integrates social sentiment signals from media and networks to capture short-term market expectations.
Risk Assessment Agent: Performs real-time legal and reputational risk evaluation through PII detection, automated GDPR/CCPA compliance checks, brand reputation keyword filtering, and unsafe content moderation APIs. Risk scores are applied as revenue deduction buffers or dataset exclusion filters.
#### **3.4.5 Value Multiplier Algorithm Description**
Following the six-dimensional base scoring, xKnown applies a Value Multiplier Algorithm to dynamically adjust the final reward weight for each data asset. At its core, the algorithm leverages an S-curve gradient function to smoothly map score intervals, preventing extreme incentive distortion at both low and high ends of the scoring spectrum.
The algorithm first calculates a base multiplier for each evaluation dimension, derived from its normalized score (0-100). Subsequently, the multiplier incorporates user-specific participation parameters drawn from the incentive layer—such as staking volume, contributor tier, and community engagement—stacking staking incentives, tier bonuses, and community contribution boosts to form the final enhancement coefficient. Throughout the computation, dimension-specific caps ensure that multiplier outputs remain within predefined system-safe boundaries to preserve platform stability.
#### **3.4.6 Evaluation Output & Pricing Delivery**
Upon completing the full assessment workflow, the system generates a comprehensive Valuation Report for each individual voice data asset. This report consolidates all six-dimensional scores, scarcity metrics, market demand forecasts, risk assessments, and fused decision outputs from both AI-driven and rule-based engines.
For example, if a data sample achieves high technical quality, rich semantic content, strong scarcity attributes, favorable market demand, and broad application potential, while maintaining minimal compliance risks, the system will assign it a higher value multiplier through this comprehensive assessment.
The resulting valuation serves as the definitive pricing reference for multiple downstream mechanisms: NFT minting, revenue sharing, staking weight allocation, and secondary market liquidity. Each valuation report remains fully traceable and explainable, providing transparent governance, transaction fairness, and ecosystem credibility.
### 3.5 Agent Workflow Orchestration
The Agent Workflow Orchestration Layer serves as the central control logic of the xKnown intelligent valuation system. Its mission is to coordinate complex multi-agent tasks into a highly efficient, scalable, and fault-tolerant end-to-end processing pipeline, ensuring stable real-time valuation even under high concurrency and heterogeneous task loads.

#### 3.5.1 Workflow-Based Agent Architecture
At the core of the orchestration design lies a workflow-driven execution framework, which decomposes the full data valuation pipeline into modular, independently executable stages. Each AI Agent is registered as a distinct node within this workflow, enabling flexible composition, parallelization, and dynamic optimization.
Key architectural principles include:
* Task modularization: Complex valuation is broken down into discrete and reusable Agent functions (e.g. transcription, semantic embedding, scene recognition, dimensional scoring).
* Directed Acyclic Graph (DAG) scheduling: Inter-task dependencies are mapped as DAG structures, ensuring strict data integrity across sequential and parallelized stages.
* Agent isolation: Each Agent operates independently, allowing flexible orchestration of AI models with varying compute demands, model sizes, and failure isolation domains.
#### 3.5.2 Workflow Engine Implementation
The orchestration engine parses and manages full pipeline execution using a DAG-based system, dynamically analyzing dependencies and optimizing compute allocation.
Core execution logic includes:
* DAG parsing and dependency resolution to derive optimal execution plans.
* Compute resource allocation based on available system GPUs, CPUs, and memory pools.
* Concurrent task scheduling for parallelizable Agents.
* Result aggregation, merging intermediate Agent outputs into unified valuation records.
* Exception handling through task retries, fallbacks, and graceful degradation under fault scenarios.
* This workflow engine ensures deterministic, explainable execution traces across billions of data records, providing both high throughput and auditability.
#### 3.5.3 Intelligent Scheduling & Optimization
To maintain optimal processing performance under fluctuating workloads, the system integrates a real-time Intelligent Workflow Scheduler that continuously monitors execution states and dynamically reallocates resources.
Key scheduling algorithms include:
* Critical Path Analysis (CPM): Identifies latency-sensitive execution chains to minimize bottlenecks.
* Resource-Constrained Optimization: Balances Agent assignments across compute clusters given GPU/CPU availability.
* Predictive Scheduling: Learns from historical execution times to anticipate future task durations.
* Dynamic Rebalancing: Actively shifts task priorities in real time based on live system load and valuation importance.
* By continuously analyzing compute saturation, task wait times, and Agent health, the scheduler ensures stable valuation output even during surges of high-value data submissions.
#### 3.5.4 Real-Time Monitoring & Failure Recovery
The Workflow Monitoring Manager operates alongside orchestration to ensure system observability, anomaly detection, and automated failure recovery.
Monitoring mechanisms include:
* Real-time metrics: Collects Agent-level execution latency, compute usage, and task success rates.
* State persistence: Logs full workflow execution checkpoints into distributed Redis clusters.
* Anomaly detection: Applies statistical models to flag abnormal execution patterns or model drifts.
* Resilient recovery: Supports checkpoint-based job restarts and fallback model substitutions upon fault triggers.
* Performance tuning: Continuously adjusts Agent resource allocation to eliminate bottlenecks.
* The orchestration layer guarantees that even under extreme workloads or partial system faults, valuation pipelines maintain both continuity and full auditability.
### 3.6 Web3-based Data Ownership and Provenance
#### **3.6.1 Ownership Logic**
* Each dataset generates a unique data hash fingerprint upon ingestion.
* Decentralized identifiers (DID) bind data to user identity.
* Smart contracts anchor ownership, timestamps, hashes, and rights on-chain.
* Ownership records are stored on public or consortium blockchains for transparency and auditability.
#### **3.6.2 Ownership Benefits**
* **Trusted Provenance:** Prevents forgery and unauthorized tampering.
* **Assetization:** Enables licensing, trading, and revenue sharing.
* **Cross-Platform Trust:** Enhances usability in multi-party collaborations.
* **Compliance & Auditing:** Satisfies regulatory traceability requirements.
### 3.7 System Security and Scalability
* End-to-end encryption across device, transmission, storage, and processing layers.
* Regulatory compliance with GDPR, CCPA, and domestic data laws.
* Full audit trails for reasoning logic, score revisions, and model versioning.